
综述:VLA如何落地医疗机器人
Embodied-ai-in-healthcare
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
---
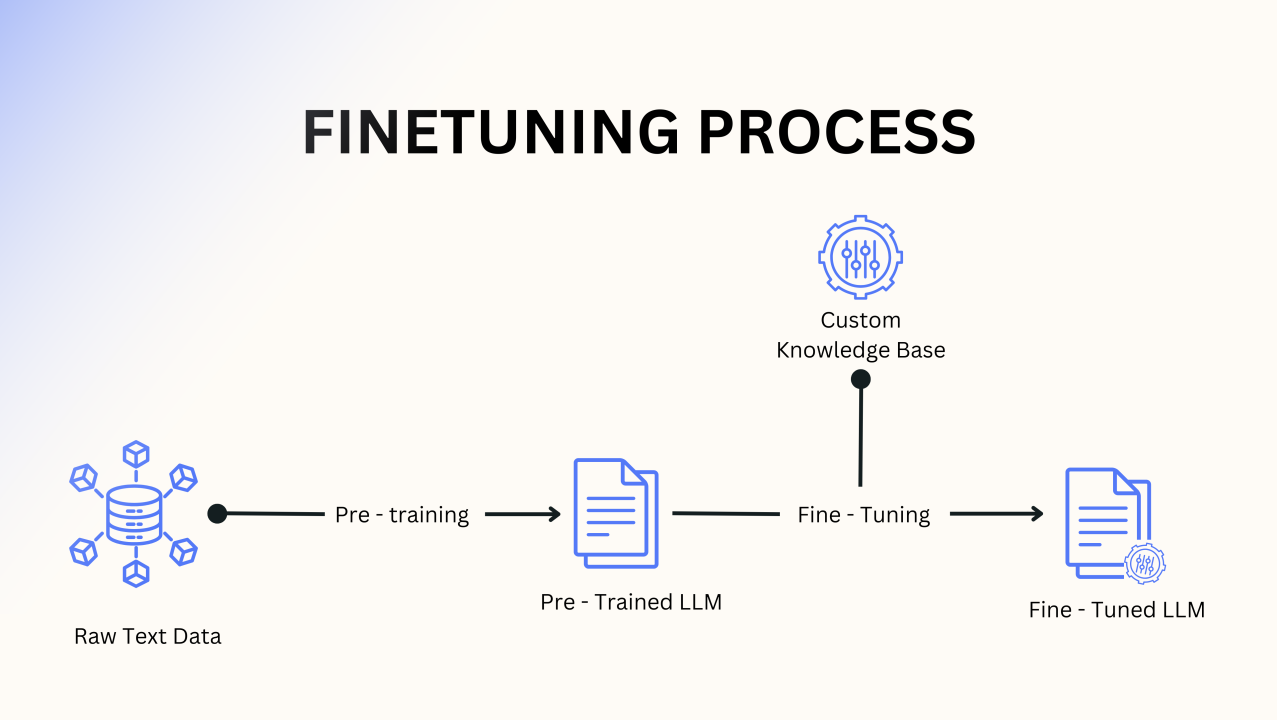
LLM finetuning practice
LLM finetune practice
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
引言
LLM finetuning technical report
LLM finetune technical blog
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
引言随着大语言模型(LLM)规模的指数级增长,传统的全量微调方法正面临前所未有的挑战:参数量爆炸导致存储成本激增,灾难性遗忘阻碍多任务学习,计算资源需求超出大多数研究者的承受能力。为了在保持模型性能的同时大幅降低计算和存储开销,研究者们提出了各种参数高效微调(Parameter-Efficient Fine-Tuning, PELT)技术。
本文系统性地梳理了当前主流的LLM微调技术全景,从最基础的BitFit到工业级标配的LoRA,从学术探索的Prefix Tuning到实用的QLoRA,再到前沿的UniPELT等组合方法。每种技术都有其独特的适用场景和权衡考量:
轻量级方法(BitFit、Prompt Tuning):专为资源极度受限的场景设计
平衡型方法(LoRA、Adapter):在性能和效率间实现最佳平衡 ...
VLA具身模型后训练综述
VLA具身模型后训练综述
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
---
① 监督式微调(SFT / Continual-FT)
开场比喻把 VLA 的预训练模型想成一位“纸上谈兵”的天才画家——他看过互联网所有名画,能描述《蒙娜丽莎》的每一笔,却从未真正拿起过画笔。监督式微调(SFT)就是给他一堂“写生速成课”:只许看老师示范 10 分钟,然后自己动笔,把眼前的苹果搬到画布上。画家依旧保留对“苹果红”“光影柔”的深刻理解,但现在必须让手腕学会“在哪儿落笔、如何运笔”。
数学舞台:条件概率的“画笔轨迹”我们把画家的写生过程写成一条“轨迹概率链”:
画苹果画苹果已落笔
每个 brushₜ 对应下一毫米画笔动作(离散化后就是 0–255 的 token)
只给“brush” token 算损失,让画家“手脑分离”——脑(视觉-语言)不动,手(动作头)狂练:
画苹果
画室里的“小灶”技巧
冻结视觉-语言层 ...

拓扑优化与CFD----高功率芯片设计微流体冷却系统
拓扑优化与CFD----高功率芯片设计微流体冷却系统
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
引言
注意到,黄大年茶思屋网站中提到了这样一篇文章,《Glacierware: Hotspot-aware Microfluidic Cooling for High TDP Chips using Topology Optimization》,这篇论文是关于高功率芯片设计微流体冷却系统的,于是,我决定写一篇关于拓扑优化与CFD的博客,来记录一下我的学习过程。同时值得注意的是,这项技术目前只有一家瑞士公司(洛桑Corintis公司)已经商业化并且尝试在迁移这套系统的应用场景,希望这篇文章能启发到更多researcher背景的公司创始人。
网站页面也给出了这项技术的主要原理和架构图,对于其底层数学的建模原理,我们后续会继续给出分析,而仿真落地的方案因为论文并未开源,目前还在探索过程中,后面有时间才会更新。
...
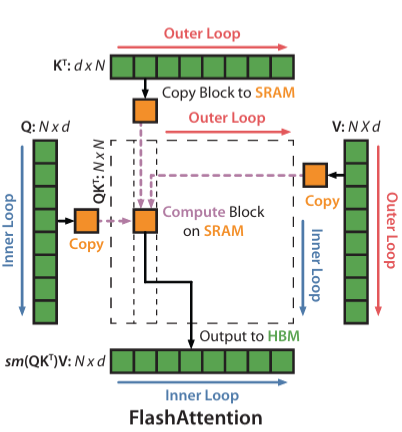
LLM底层架构---手撕flashattention1
LLM底层架构---手撕flashattention1
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
引言FlashAttention是近年来为优化自注意力机制(Self-Attention)而提出的一种高效算法,旨在解决传统注意力机制在大规模模型训练中的内存和计算瓶颈问题。其通过在硬件层面优化内存访问和计算策略,实现了显著的加速效果,尤其适用于大规模模型的训练。在其原始论文中(FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Aware Computation),作者提出了一种基于硬件友好的设计,使得计算过程中内存使用更加高效,从而加速了训练过程。FlashAttention 在保持精度的同时,显著降低了对 GPU 显存的需求和内存带宽的消耗。本文章参考了李理的博客(FlashAttention: 高效注意力机制的实现与优化),结合 ...
LLM分布式训练3---并行策略之流水线并行
LLM分布式训练3---并行策略之流水线并行
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的并行策略—-流水线并行。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例
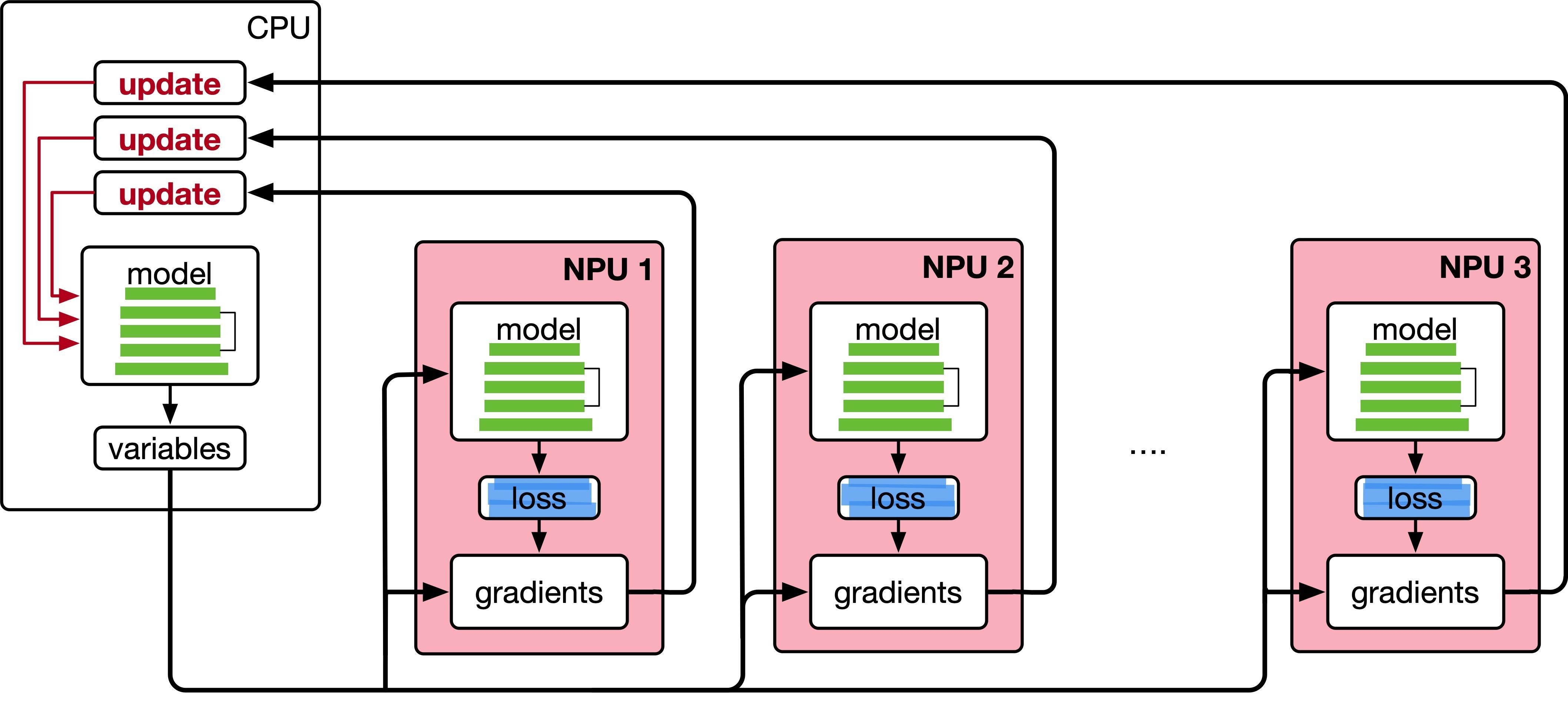
LLM分布式训练2---并行策略之数据并行
LLM分布式训练2---并行策略之数据并行
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的并行策略。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例
数据并行的数学原理数据并行的核心思想是将整个神经网络模型复制到多个计算设备上,并将训练数据分成若干子集,分配到每个计算设备上。每个计算设备独立进行前向传播和反向传播,计算出本地的梯度,并将所有设备的梯度汇总以更新模型。这个过程的关键在于梯度的同步和平均。
在数据并行系统中,每个计算设备都有整个神经网络模型的模型副本(Model Replica),进行并行计算。每个计算设备只分配一个批次数据样本的子集 ...
LLM分布式训练4---Deepspeed实操
LLM分布式训练4---Deepspeed实操
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的Deepspeed实操。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例
LLM分布式训练3---集群架构
LLM分布式训练3---集群架构
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的并行策略。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例