LLM分布式训练1---基础知识篇
LLM分布式训练1---基础知识篇
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
引言
随着大语言模型参数量和所需训练数据量的急速增长,单个机器上有限的资源已无法满足其训练的要求。需要设计分布式训练系统来解决海量的计算和内存资源需求问题。在分布式训练系统环境下,需要将一个模型训练任务拆分成多个子任务,并将子任务分发给多个计算设备,从而解决资源瓶颈。如何才能利用数万个计算加速芯片的集群,训练千亿甚至万亿个参数量的大语言模型?这其中涉及集群架构、并行策略、模型架构、内存优化、计算优化等一系列的技术。
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的基础概念。
分布式训练概述
概念
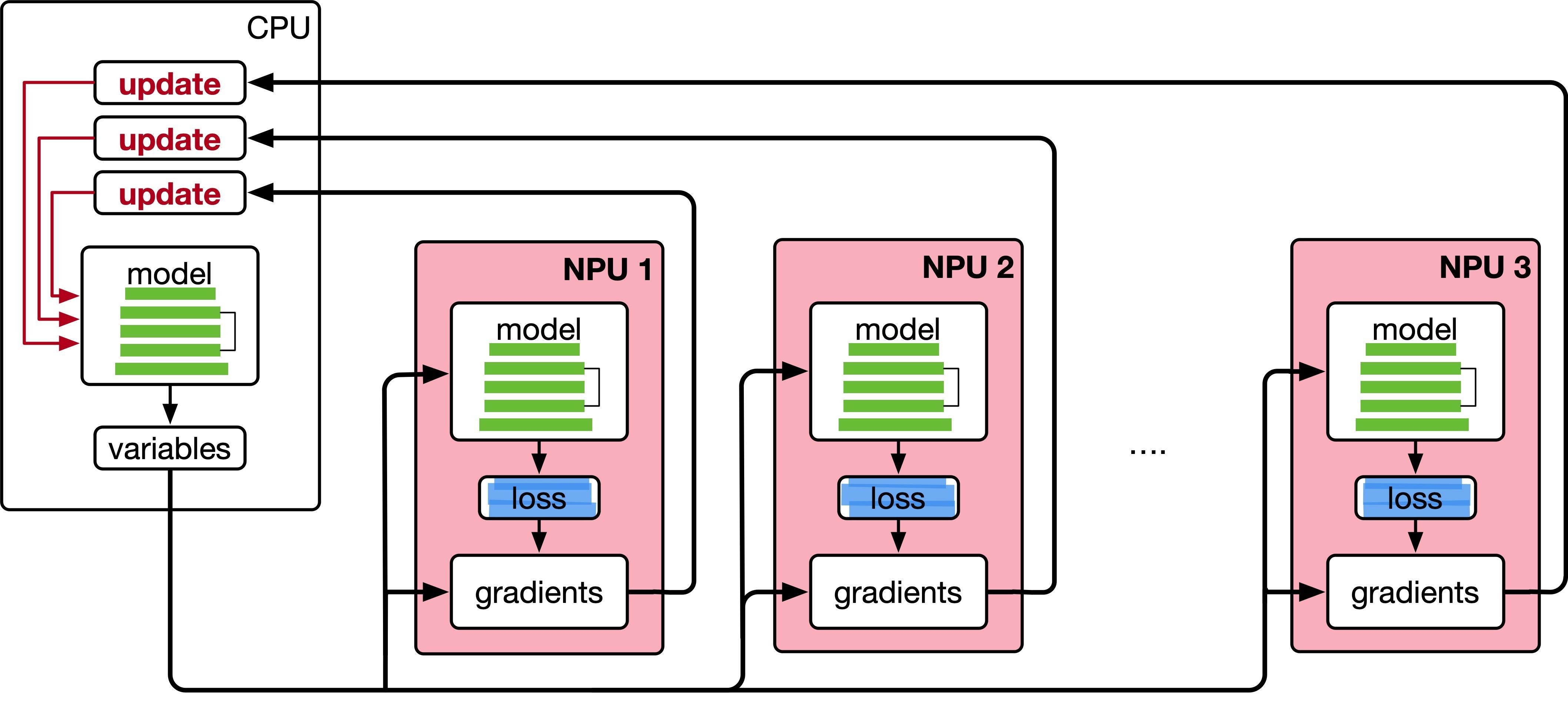
分布式训练(Distributed Training)是机器学习中提升训练速度和效率的一个重要技术。简单来说,它是通过多个计算设备同时协作,分担巨大的计算任务,从而加速深度学习模型的训练过程。通常,我们会看到中央处理单元(CPU)、图形处理单元(GPU)、张量处理单元(TPU)和神经网络处理单元(NPU)等不同的硬件在这种系统中协同工作。
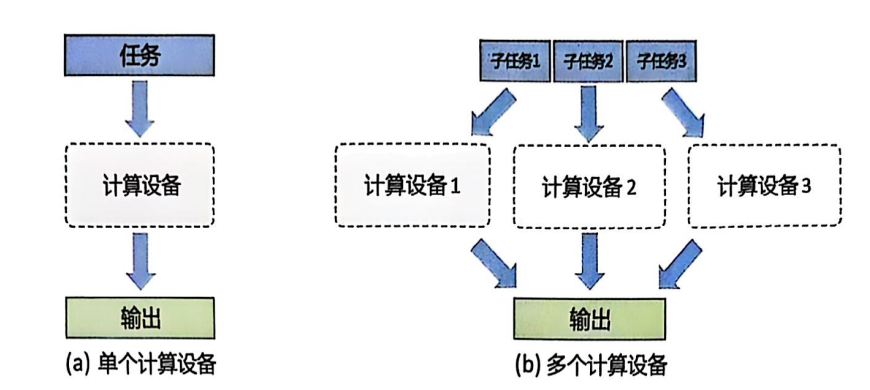
分布式训练过程中,一个模型训练任务往往会有大量的训练样本作为输入,可以利用一个计算设备完成,也可以将整个模型的训练任务拆分成多个子任务,分发给不同的计算设备,实现并行计算。此后,还需要对每个计算设备的输出进行合并,最终得到与单个计算设备等价的计算结果。由于 每个计算设备只需要负责子任务,并且多个计算设备可以并行执行,因此其可以更快速地完成整 体计算,并最终实现对整个计算过程的加速。
算力不足
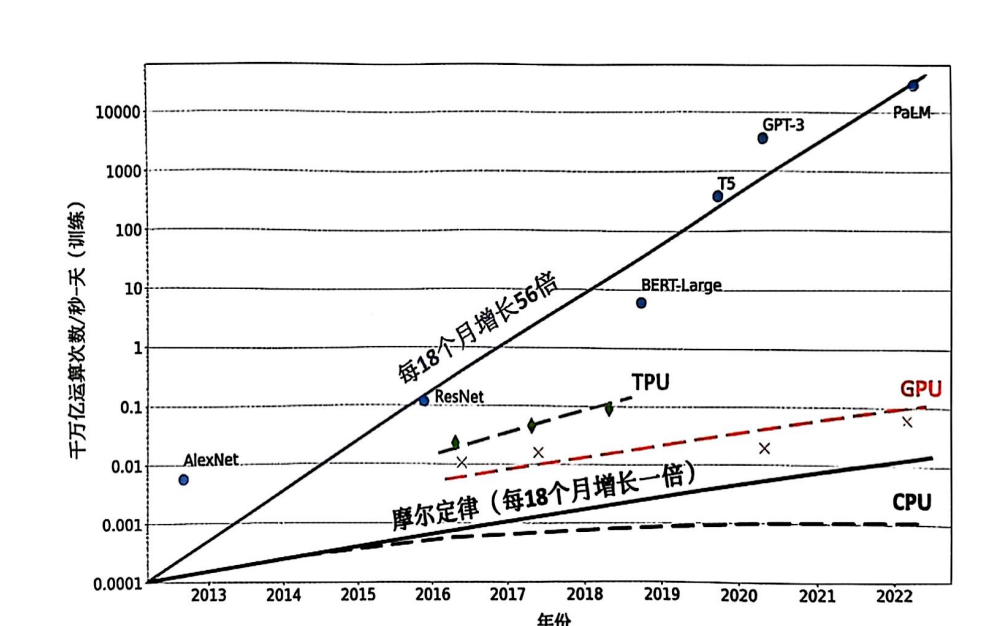
促使人们设计分布式训练系统的一个最重要的原因是单个计算设备的算力已经不足以支撑模型训练。图2给出了机器学习模型对于算力的需求以及同期单个计算设备能够提供的算力。机器学习模型快速发展,从2013年AlexNet 被提出开始,到2022年拥有5400亿个参数的PaLM 模型被提出,机器学习模型以每18个月增长56倍的速度发展。模型参数规模增大的同时,对训 练数据量的要求也呈指数级增长,这更加剧了对算力的需求。然而,近几年,CPU算力增加已 经远低于摩尔定律(Moore’s Law),虽然计算加速设备(如GPU、TPU等)为机器学习模型提供了大量的算力,但是其增长速度仍然没有突破每18个月翻倍的摩尔定律。只有通过分布式训练系统才可以匹配模型不断增长的算力需求,满足机器学习模型的发展需要。
模型所需硬件配置
下面这个表格提供了几种大型语言模型(LLM)训练所需的硬件配置、GPU数量和训练时间的详细信息。GPT-3 使用了 992块 NVIDIA A100 80GB GPU,并利用全数据并行和张量并行技术,在大约 2个月 内完成训练。OPT 模型同样使用了 384个 A100 GPU,训练时通过 4x NVLink 高速通信,训练时间也大约为 2个月。
BLOOM 模型的训练则使用了 384个 A100 GPU,训练时间为 3.5个月,并且采用了 Omni-Path 网络进行通信。与之相比,LLama 系列模型的训练所需的 GPU 数量和时间更为庞大。例如,LLama-65B 模型的训练需要超过 1百万个 GPU,且其数据集规模异常庞大。
这些模型的训练展现了当前超大规模语言模型所需的巨大计算资源,并且它们的训练时间与硬件配置的要求密切相关。为了更高效地训练这些模型,研究者们不断优化计算框架与硬件利用效率。
| 模型/框架 | 使用的硬件 | GPU数量 | 训练时间 | 网络与通信 | 备注 |
|---|---|---|---|---|---|
| GPT-3 | NVIDIA V100 GPU, NVIDIA A100 80GB GPU | 992块 A100 80GB GPU | 约2个月 | Omni-Path 100 Gbps | 全数据并行(Fully Sharded Data Parallel)与张量并行(Tensor Parallelism) |
| OPT | NVIDIA V100 GPU, A100 80GB GPU | 48个节点,总共384个GPU | 约2个月 | 4x NVLink用于节点间GPU通信 | 使用Megatron-LM框架 |
| BLOOM | NVIDIA A100 80GB GPU | 384个GPU | 3.5个月 | Omni-Path网络 | 开源模型,支持多语言 |
| LLama (LLama-7B) | NVIDIA A100 80GB GPU | 82,432个GPU | 约135,168 GPU小时 | NVLink | 适用于多种下游任务 |
| LLama (LLama-13B) | NVIDIA A100 80GB GPU | 135,168个GPU | 约530,432 GPU小时 | NVLink | 适用于多种下游任务 |
| LLama (LLama-65B) | NVIDIA A100 80GB GPU | 1,022,362个GPU | 约1,000,000 GPU小时 | NVLink | 数据集极其庞大,训练成本高 |
分布式训练建模
单设备计算速度
单设备的计算速度
其中,计算能力
其中,
计算设备总量
在分布式训练中,计算设备的总数量为
多设备加速比
多设备加速比
其中,
总训练速度
将以上各个部分结合,总训练速度
代入
优化目标
优化的目标是最大化总训练速度
这个优化问题的核心是如何选择适当的设备数量
通过求解这个优化问题,我们可以得到一个最优的设备数量
分布式训练挑战
通过使用分布式训练系统,大语言模型的训练周期可以从单计算设备花费几十年,缩短到使 用数千个计算设备花费几十天。分布式训练系统需要克服计算墙、显存墙、通信墙等挑战,以确保集群内的所有资源得到充分利用,从而加速训练过程并缩短训练周期。
计算墙和显存墙源于单计算设备的计算和存储能力有限,与模型所需庞大计算和存储需求存 在矛盾。这个问题可以通过采用分布式训练的方法解决,但分布式训练又会面临通信墙的挑战。在 多机多卡的训练中,这些问题逐渐显现。随着大语言模型参数的增大,对应的集群规模也随之增 加,这些问题变得更加突出。同时,当大型集群进行长时间训练时,设备故障可能会影响或中断 训练,对分布式系统的问题处理也提出了很高的要求。
计算能力需求
GPT-3 的计算需求:
GPT-3 需要进行巨大的浮点计算,计算需求达到 314 ZFLOPS。NVIDIA H100 的计算能力:
单台 NVIDIA H100 GPU 的计算能力为 2000 TFLOPS。计算能力差距:
计算能力差距表明,GPT-3 需要的计算能力是单台 H100 GPU 的 约 157 亿倍。
存储需求
GPT-3 的参数数量:
GPT-3 拥有 1750 亿个参数。单个参数存储需求:
- 如果采用 FP32 精度存储,每个参数需要 4 字节(32 位)。
所需总存储量:
GPT-3 模型所需的存储总量为 700 GB。存储问题:
单个 NVIDIA H100 GPU 的显存为 80GB,因此,单个 GPU 并不能存储整个模型的参数。为了存储所有的参数,需要采用分布式存储。
通信带宽需求
假设每轮训练需要传输的数据量为 D,并且我们有 N 个计算节点进行分布式训练。
- 带宽需求:
其中:是所需的带宽。 是每轮训练中需要传输的数据量。 是训练的时间。
考虑到 GPT-3 训练过程中需要传输数百 TB 的数据(例如:模型参数、梯度、激活值等),如果每个节点的带宽为 800 Gbps,而训练过程需要多次进行节点间的数据交换,带宽可能成为训练的瓶颈。
结果总结
- 计算能力需求:GPT-3 的计算需求比单个 NVIDIA H100 GPU 高出约 157 亿倍,说明在单节点无法满足训练需求的情况下,必须采用大规模分布式训练。
- 存储需求:GPT-3 模型需要约 700GB 的存储空间,单个 GPU 显存(80GB)远不足以容纳整个模型,因此必须分布存储。
- 通信带宽需求:分布式训练中,数据传输带宽成为瓶颈问题,可能需要优化网络配置和传输策略。
分布式训练方法论
分布式训练是解决大规模模型训练时计算、存储和带宽瓶颈的有效手段。为了加速训练过程并充分利用计算资源,分布式训练采用了多种并行策略和技术。以下是主要方法论的总结,也是后面几张的重点内容:
1. 数据并行(Data Parallelism)
数据并行将训练数据划分成多个小批次,每个设备处理不同的数据子集。每个设备上有相同的模型副本,进行梯度计算后通过通信同步梯度。这种方法的加速比随着设备数量增加而递减,由于通信开销的存在。
2. 模型并行(Model Parallelism)
模型并行用于处理超大模型,其参数无法完全加载到单个设备显存中。在模型并行中,模型被划分为多个部分,分布在多个设备上,每个设备只计算模型的一部分。由于频繁的设备间通信,通信开销是模型并行的一个重要考虑因素。
3. 混合并行(Hybrid Parallelism)
混合并行结合了数据并行和模型并行的优势,适用于非常大规模的模型。它有效平衡了计算负载和通信负载,能充分利用设备资源,同时减轻单一并行方法的局限性。
4. 异步训练(Asynchronous Training)
异步训练允许每个设备独立更新其参数,避免了同步等待,减少了通信开销。虽然它能提高训练速度,但也可能导致梯度更新不一致,影响训练的稳定性。
5. 集群架构与落地
在实际的分布式训练中,集群架构的选择非常重要。常见的架构有共享存储和分布式存储两种方式。共享存储适用于带宽充足的场景,而分布式存储则适用于存储规模大且带宽需求较低的环境。
6. 容错与恢复
在分布式训练中,由于设备故障的高频发生,容错机制是必不可少的。常见的容错策略包括定期保存模型状态的检查点和任务重启功能。这些策略能确保在设备故障时,训练能够迅速恢复,减少训练中断的影响。
7. 性能评估
分布式训练系统的性能评估需要综合考虑计算能力、通信延迟、设备故障率等因素。通过模拟不同配置下的训练时间,可以找到最优的集群规模和训练策略。
总结
分布式训练的核心目标是通过合理的并行策略、优化通信开销、提高计算效率和减少存储瓶颈来加速训练过程。结合数据并行、模型并行、混合并行等策略,并针对集群架构和容错问题进行优化,能够有效提升大规模模型训练的效率和性能。