LLM分布式训练2---并行策略之数据并行
LLM分布式训练2---并行策略之数据并行
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的并行策略。
数据并行的数学原理
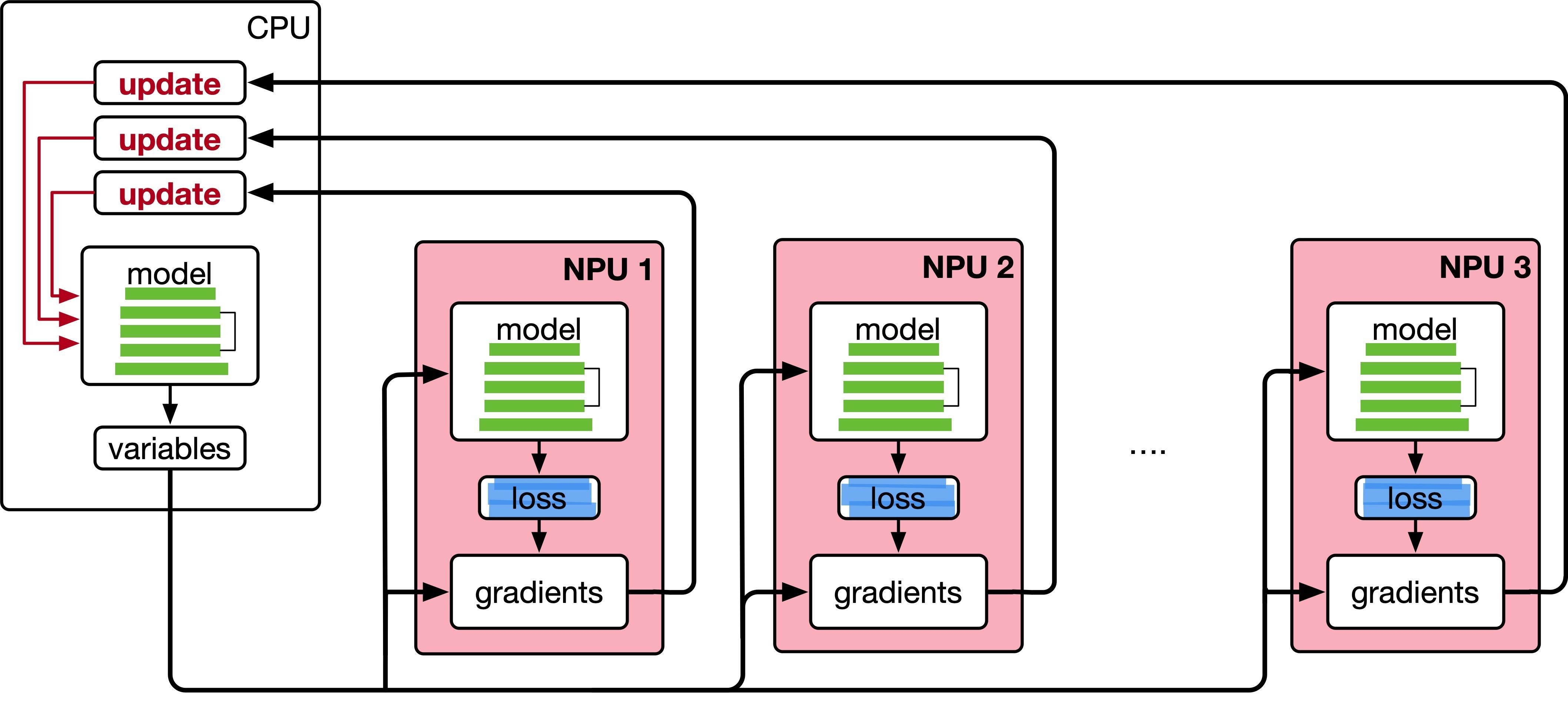
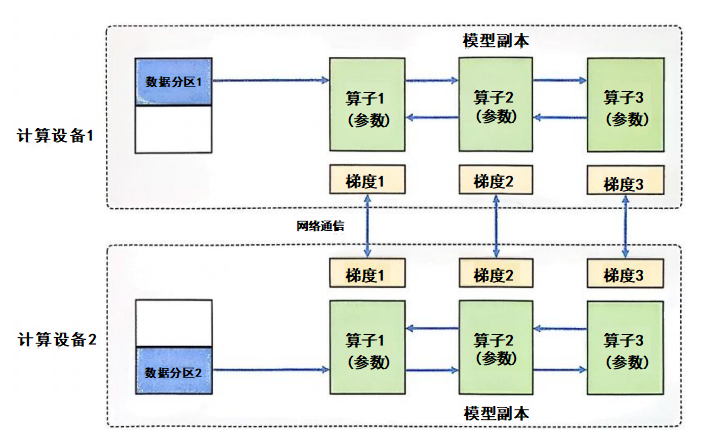
数据并行的核心思想是将整个神经网络模型复制到多个计算设备上,并将训练数据分成若干子集,分配到每个计算设备上。每个计算设备独立进行前向传播和反向传播,计算出本地的梯度,并将所有设备的梯度汇总以更新模型。这个过程的关键在于梯度的同步和平均。
在数据并行系统中,每个计算设备都有整个神经网络模型的模型副本(Model Replica),进行并行计算。每个计算设备只分配一个批次数据样本的子集,并根据该批次数据样本进行网络模型的前向计算。假设一个批次的训练样本数量为N,使用M个计算设备并行计算,每个计算设备会分配到
训练过程的数学公式
假设我们有一个神经网络模型
前向传播
每个设备
损失计算
每个设备
其中,
反向传播
每个设备根据本地数据计算梯度
梯度聚合
所有设备的梯度将被汇总(通常是通过平均),然后每个设备的梯度更新模型参数
其中,
模型更新
使用汇总后的平均梯度更新模型参数:
其中,
数据并行代码的对应
在 PyTorch 中,数据并行的实现通常使用 nn.DataParallel 或 nn.DistributedDataParallel。通过这些工具,我们可以将上述的数学过程映射到实际的代码中。
前向传播和损失计算
1 | class Model(nn.Module): |
· 前向传播公式:每个设备计算
使用 DataParallel 进行数据并行
1 | if torch.cuda.device_count() > 1: |
· 并行计算公式:模型被复制到每个设备上,并在每个设备上计算前向传播。
梯度计算和聚合
1 | output = model(input) # 计算前向传播 |
反向传播公式:loss.backward() 计算每个设备上的梯度
梯度同步和平均
在 nn.DataParallel 中,PyTorch 会自动处理梯度的汇总。具体来说,它会在每次反向传播时将各设备上的梯度进行汇总,并同步到模型的主设备(通常是第一个设备)。
模型参数更新
1 | optimizer.step() # 更新模型参数 |
· 参数更新公式:optimizer.step() 根据平均梯度来更新模型参数
结论
数据并行的核心思想是通过将数据划分为多个子集,并在多个计算设备上并行计算每个子集的前向传播和反向传播,最终聚合梯度并更新模型。在 PyTorch 中,nn.DataParallel 提供了自动化的方式来处理数据并行,包括前向传播的分配、梯度的聚合以及参数更新等。通过这个机制,我们可以高效地利用多个 GPU 来加速训练过程。
完整代码
1 | import torch |
当你运行这段代码时,你会看到类似以下的输出:
1 | 我们将使用 2 个GPU! |
数据并行训练实战
使用 DistributedSampler 和 DistributedDataParallel 进行分布式训练。通过 DistributedSampler,数据集会被均匀划分到每个GPU上,确保每个GPU处理不同的数据,从而实现数据并行;而 DistributedDataParallel 会在每个GPU上复制模型,并在训练过程中同步梯度,实现高效的分布式训练。
创建 DistributedSampler 类
DistributedSampler 旨在将数据集的样本分配到不同的计算设备上。它将数据集的样本随机打乱并按设备数量分配,确保每个设备得到不同的训练样本。以下是实现 DistributedSampler 类的代码:
1 | import torch |
这个类实现了分布式数据加载器,通过__iter__方法根据进程的rank分配数据,确保每个进程处理的数据不重叠,并且每个进程处理的数据量相同。set_epoch方法用于设置当前训练的epoch,确保每个训练轮次的打乱顺序不同。
完整的训练程序样例 main.py
以下是利用 DistributedSampler 进行训练的完整示例:
1 | import argparse |
启动分布式训练
使用以下命令行启动训练程序:
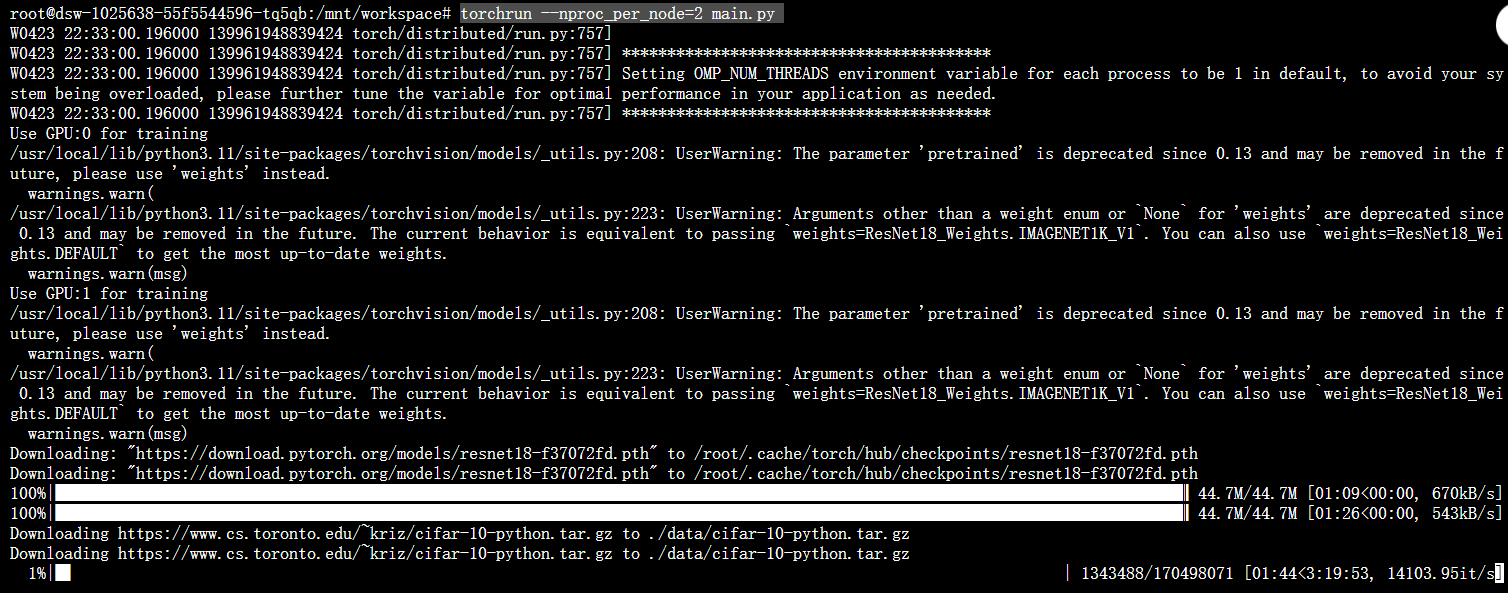
1 | torchrun --nproc_per_node=2 main.py |
其中,--nproc_per_node=2表示使用2个进程进行训练,每个进程对应一个GPU。
你会看到每个GPU的输入、输出和损失信息,以及每个epoch的损失信息。
1 | Use GPU:0 for training |
这里直接下载数据有点慢,可以手动下载数据集解压,然后修改代码中的数据集路径。
下载 CIFAR-10 数据集
1 | wget https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz |
或者可以到这个链接下载:[cifar数据下载链接](https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz)
解压 CIFAR-10 数据集
1 | tar -xvzf cifar-10-python.tar.gz -C ./data |
这个命令会将 CIFAR-10 数据集解压到 ./data 目录下。确认解压后的目录结构如下:
1 | ./data |
然后你就可以开始运行代码了。