VLA具身模型后训练综述
VLA具身模型后训练综述
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
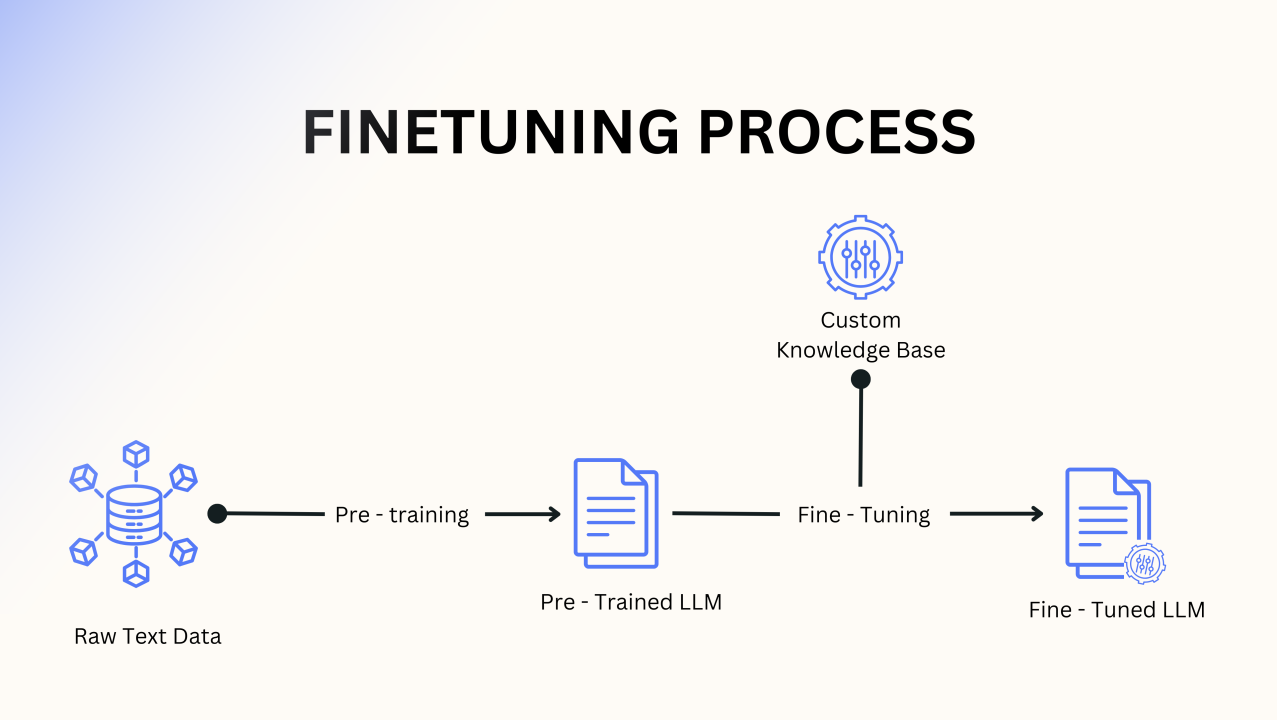
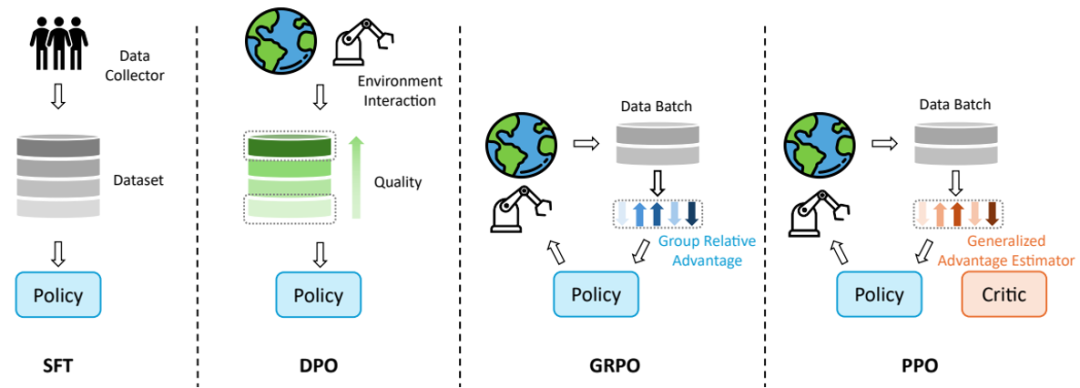
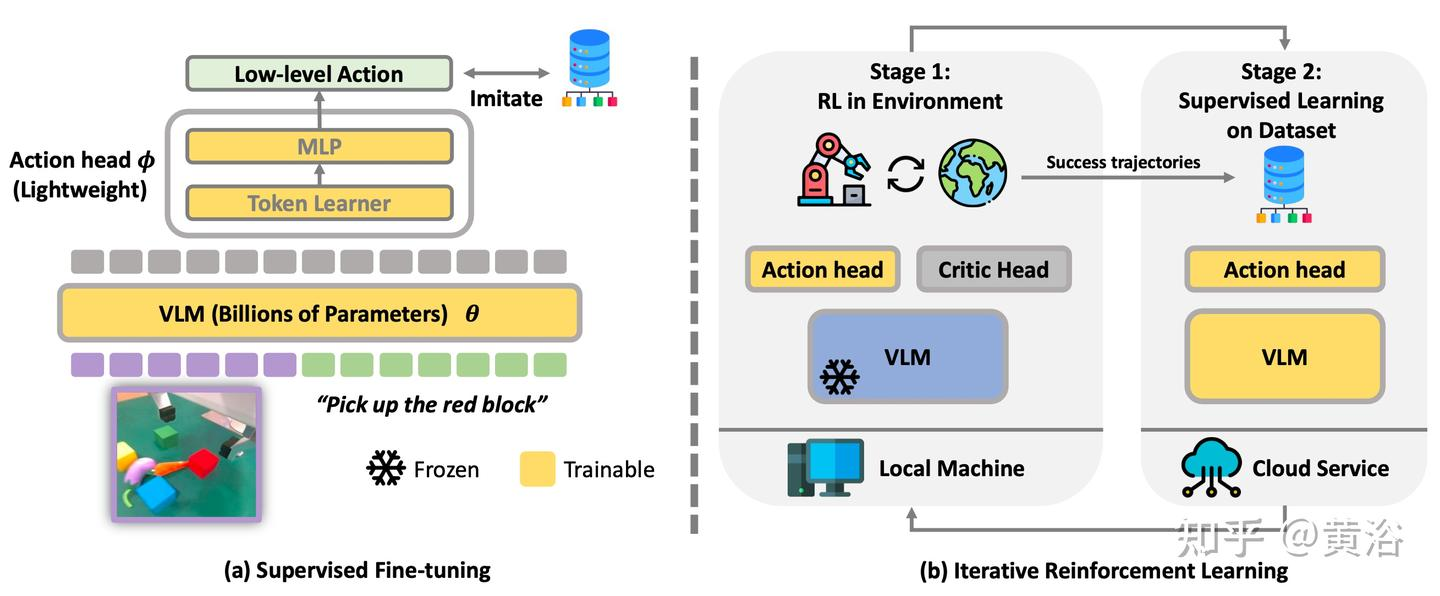
① 监督式微调(SFT / Continual-FT)
开场比喻
把 VLA 的预训练模型想成一位“纸上谈兵”的天才画家——他看过互联网所有名画,能描述《蒙娜丽莎》的每一笔,却从未真正拿起过画笔。监督式微调(SFT)就是给他一堂“写生速成课”:只许看老师示范 10 分钟,然后自己动笔,把眼前的苹果搬到画布上。画家依旧保留对“苹果红”“光影柔”的深刻理解,但现在必须让手腕学会“在哪儿落笔、如何运笔”。
数学舞台:条件概率的“画笔轨迹”
我们把画家的写生过程写成一条“轨迹概率链”:
- 每个 brushₜ 对应下一毫米画笔动作(离散化后就是 0–255 的 token)
- 只给“brush” token 算损失,让画家“手脑分离”——脑(视觉-语言)不动,手(动作头)狂练:
画室里的“小灶”技巧
- 冻结视觉-语言层 = 给画家戴上“思想手铐”:不许改审美,只许练手速
- LoRA 低秩适配器 = 在手腕贴“肌肉记忆贴”,轻轻微调 0.1% 参数,就能让笔触更顺滑
- 离散化画笔 = 把连续颜料盘切成 256 格调色板——格子太细,画家记不过来;太粗,画不出细腻弧。实验发现 7-bit(128 格)最像“黄金分割”
写生结果
10 次示范后,画家不仅能把“这颗苹果”画得惟妙惟肖,还能零样本迁移到“梨”“橙子”——因为视觉语义区里“圆+红+高光”早已是邻居。这就是 SFT 的魔法:小数据(几百轨迹)→ 大泛化(万千物体),而且 8×A100 一晚毕业,堪称“机器人界的速成班”。
谢幕金句
SFT 让 VLA 完成从“艺术评论家”到“新锐画师”的华丽转身——脑袋依旧博览群书,双手却已能妙笔生花;
接下来,他只需再上几堂“偏好大师课”或“在线写生营”,就能成为真正的“具身艺术大师”。
代表论文
| 方法 | 会议 | 关键贡献 | 代码/数据 |
|---|---|---|---|
| OpenVLA-SFT | CORL’24 | 7B 模型,8×A100 一天内吞 200k OXE 轨迹;提出“仅回归 action token”混合损失 | github |
| CAST | arXiv25 | 反事实 SFT:自动生成「负面指令-失败轨迹」与「正面指令-成功轨迹」对,长序列任务指令遵循率↑12% | github |
| Hi-Lo VLA | ICRA’25 | 分层 SFT:高层 VLM 规划子目标,低层 1B 小模型做 100 Hz 实时动作,避免重训大模型 | github |
| MoE-SFT | RSS’25 | 混合专家 SFT:按机器人形态(arm/drone/hand)自动路由专家,单模型服务 4 种本体 | github |
1. OpenVLA-SFT|“八卡一日速成班”
故事你新开了家奶茶连锁,急需 1000 名“调饮师”。可老师傅只有 200 人,怎么办?OpenVLA-SFT 像一台“克隆机”:把 200 位师傅的“看单→配料→封口”整套动作录成 20 万条轨迹,一股脑喂给 7 B 大模型。八块 A100 当“八口大锅”,熬 24 小时,模型就只学“手该怎么动”,配料常识一律不动。第二天,每台店门口站着的,就是一位“零失误新手”——一天复制 1000 名老师傅,配方比例、封口力度一模一样。
落地场景食品、3C 装配线“技能复制”:少量熟练工示范→一夜批量“青工上线”,无需重训大模型,产线换型只需再录一天数据。
- CAST|“失败博物馆”里的反教科
故事驾校教练常说:“别走那条道,上次有人撞树!”这就是反事实教材。CAST 自动开一座“失败博物馆”:同样一句“把杯子放进抽屉”,它先让模型瞎开 100 条轨迹——撞翻、掉落、远投应有尽有,再把“唯一成功”那条标成“正面”。于是学员(模型)一边看“正面”,一边被提醒“负面长啥样”,长序列驾驶(倒车入库、侧方停车)一次就过,通过率↑12%。
落地场景自动驾驶实训、无人机绕障——失败数据便宜又海量,让模型“避坑”比“找最优”更高效。
3. Hi-Lo VLA|“大脑写剧本,小脑演功夫”
故事舞台魔术表演,导演在耳麦里低声说:“下一步,把鸽子移到左手。”魔术师手速快得观众看不清。Hi-Lo 把 7 B VLM 当导演,只负责“慢思考”——每 1 秒给出子目标:“抓杯→移杯→倒奶”;1 B 小模型才是魔术师,100 Hz 实时输出腕部角度,观众(机器人)看到的永远是流畅魔术。导演不用练肌肉,魔术师也不用懂剧本,两层各干各的,大模型从此不必重训。
落地场景舞台机器人、直播带货双臂协作——既要“长思考”编排流程,又要“短反应”不卡帧,分层最香。
4. MoE-SFT|“瑞士军刀”一专多能
故事你背包里只想带一把刀,却希望能削苹果、剪鱼线、拧螺丝。MoE-SFT 把四位专家塞进同一把“刀”:
- 机械臂专家专精“拧螺丝”
- 无人机专家专精“空中拍照”
- 灵巧手专家专精“捏芯片”
- 移动底盘专家专精“绕障滑行”
② 偏好优化(DPO / GRAPE )github
开场比喻
SFT 毕业的天才画家已经能把苹果原封不动搬到画布上,可顾客却挑刺:“左边那幅光影太硬,右边这幅才柔和!我要右边!”
偏好优化就是“顾客点评班”——不再给画家示范“怎么画”,而是递给他两幅成品,只说一句话:“左边差评,右边好评,你自己悟!”画家无需重写笔触公式,只需把“好评”的轨迹概率推高,把“差评”的压扁,几番对比下来,顾客满意度蹭蹭上涨。
数学舞台:对比式“审美跷跷板”
把顾客的两句话正式写进 loss,形成 DPO 的“跷跷板”:
- x =“请画一只带露珠的苹果”
- yw = 顾客点赞的“柔光水珠版”轨迹
- yl = 顾客嫌弃的“塑料反光版”轨迹
- πref 是 SFT 毕业时的“原版画家”
- β 像“顾客挑剔度”——越大,画家越激进地拉开好坏差距
整个训练零真实动作标签,只靠“哪幅更顺眼”的对比信号,就能让画笔悄悄偏向人心。
写生结果
经过偏好跷跷板,画家笔下的苹果出现“顾客潜意识”里的细节:
- 高光柔和——不刺眼
- 边缘略显毛茸茸——更自然
- 握笔力度轻——避免“刀刻”感
更妙的是,他没重新学素描,只是让“好评”轨迹的概率密度悄悄膨胀——就像把气球往好评方向轻吹一口气。
谢幕金句
偏好优化让 VLA 从“会画”升级为“画得讨喜”——不再死记硬背示范,而是读懂人心天平;下一站上线的“在线强化写生营”,将让画家第一次离开画室,去街头实景写生,真正面对光影变幻、行人穿梭的复杂世界!
代表论文
| 方法 | 会议 | 关键贡献 | 代码/数据 |
|---|---|---|---|
| RIPT-VLA | arXiv25 | 人5 min 标注一次偏好 → DPO + 在线 RL 交替;真机 50 轮收敛 | github |
| GRAPE | ICLR’25 | 群组相对偏好:同一指令下采样 8 条轨迹,按 GT 成功率排序,直接优化排名 | github |
| Tactile-DPO | RSS’25 | 首次把「力觉图像」token 化,用触觉-视觉配对做偏好,提升接触-rich 任务 15% 成功率 | github |
| ChatVLA-Prefer | arXiv25 | 对话式偏好:用户用自然语言纠正动作 → 自动转成偏好对,支持连续多轮修正 | github |
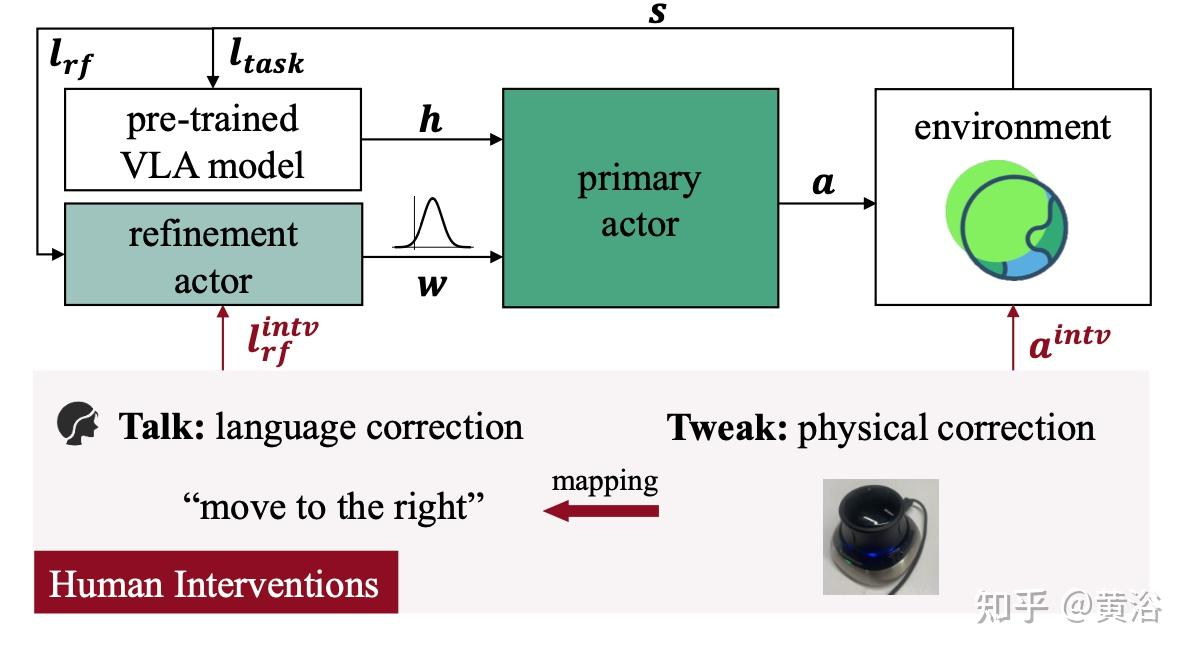
1. RIPT-VLA|“5 分钟打卡的魔鬼教练”
场景漫画真机车间里,机器人正给手机贴保护膜。教练(人类)端着咖啡,每 5 min 晃过来一次:
- “左边气泡多,差评❌”
- “右边无气泡,好评✅”打完工牌,教练闪人。机器人立刻用 DPO 把“右边”升星、把“左边”降权,再自己 RL rollout 几把巩固记忆。50 轮打卡下来,贴膜成功率从 60% → 95%,教练还没喝完第三杯咖啡。
落地3C 装配、精密贴装——人类懒得写详细奖励函数,就适合“路过式”点赞。
2. GRAPE|“8 人成团选秀赛”
场景漫画导演一声 “Action!”——8 台无人机同时接到指令:“绕樱花树飞 8 字”。航拍画面实时回传,评委(GT 成功率)秒给排名:1>2>…>8。GRAPE 把头部 3 台 vs 尾部 3 台直接拖进“跷跷板”——“好轨迹”上热搜,“差轨迹”被踩扁,一次更新就把 8 条样本吃干榨尽。样本效率×3,导演笑称:“别人一对一 PK,我一次成团出道。”
落地集群无人机表演、仓储 AMR 车队——群体数据便宜,排个名就能训。
3. Tactile-DPO|“指尖的恋爱滤镜”
场景漫画夜晚,机器人给手机打螺丝。摄像头只看见“黑壳”,根本分不清是否“滑牙”。突然,力觉相机亮起——像给指尖装了恋爱滤镜:
- 划痕太刮手 → 差评💔
- 扭矩刚好、表面圆润 → 好评💖Tactile-DPO 把“力觉图像”切成 token,跟视觉-语言一起塞进口味对比。10 轮后,机器人学会“温柔又不失力道”,滑牙率降 15%,手机壳摸起来像婴儿皮肤。
落地精密装配、抛光、去毛刺——视觉盲区大,把“手感”变 token 才能细修。
4. ChatVLA-Prefer|“话痨用户的实时改图器”
场景漫画厨房 newbie 机器人正给披萨撒芝士。远程的用户视频连线:“太多了,左边减少 10 g!”“芝士要撒成螺旋,不要天女散花!”每句吐槽自动转偏好对——旧轨迹=差评,立即重做的轨迹=好评;DPO 当场升权。用户话还没说完,机械手已悄悄把芝士边缘补成完美螺旋,弹幕刷屏:“它听得懂人话!”
落地远程家政、餐饮机器人——顾客就是产品经理,边聊天边微调,零代码迭代。
③ 在线强化学习(PPO / TRPO / 轨迹级)
开场比喻
SFT 画家已经能画出顾客点赞的苹果,可世界是会动的——灯光明暗、桌布滑动、苹果突然滚落!在线 RL 就像把画家直接推上街头速写擂台:
- 每 5 秒换一位路人模特
- 画完当场拍卖,价高(奖励)立即到账
- 兜里金币越多,画笔调子越稳
画家一边咬牙“啊啊啊下次一定更好”,一边实时改笔法——这就是在线强化学习:用刚发生的轨迹当考题,用奖励当分数,立刻交卷立刻改错!
数学舞台:轨迹级“打怪爆金币”概率游戏
把整条轨迹 τ 当成一把“副本通关录像”:
画家要最大化期望金币(奖励和):
但街头擂台输赢方差巨大,于是 PPO 给画家一条“安全绳”——只许在旧策略 π_old 的 ±ε 小圈内更新(ε≈0.2),防止手抖把画笔甩飞:
- A_t 是“ Advantage 金币差”——同状态下这步比平均好多少
- clip 像安全护栏:太好高骛远?拉回圈内。
写生结果
画家在街头摸爬滚打 50 回合后:
- 灯突然暗 → 他自动加深阴影 token
- 苹果滚半圈 → 他实时调视角补画
- 路人突然伸手 → 他停笔等干扰消失
零-shot 应对动态世界,成功率曲线像股票涨停——因为每一次“亏钱”都立刻变成“改笔画”。
谢幕金句
在线 RL 是 VLA 的“社会大学”——不再靠老师示范,而是靠世界给反馈;画家走出画室,才终于明白:真正的艺术,不是在静物前复制,而是在变幻中持续写生!
代表论文
| 方法 | 会议 | 关键贡献 | 代码/数据 |
|---|---|---|---|
| VLA-RL | arXiv25 | 整条轨迹当「多轮对话」,PRM 给稀疏奖励,PPO 在线更新;Libero 成功率↑18% | github |
| RFTF | arXiv25 | 无需动作标签,利用「越靠后状态越优」时序先验学价值函数,再引导 PPO | |
| TGRPO | arXiv25 | 轨迹级 Group-Relative PPO:按 GT 成功率分组,减少方差,样本效率×3 | |
| iRe-VLA | ICRA’25 | 异步并行:仿真器 256 核同时出轨迹,GPU 端即时 roll-out,一天等效 10M 真机交互 |
1. VLA-RL|「把整条轨迹当聊天记录」
场景漫画Libero 厨房里,机械臂端着锅铲炒蛋。PRM 老师只站在门口,每 30 秒才喊一次分:“蛋没翻→0 分;翻成功→1 分”——稀疏得像期末考试只给总分。VLA-RL 把“翻蛋”一整段轨迹当成微信长消息,每一步 brush token 就是一句“语音”。PPO 当“班主任”,用最终分反向润色每一句话——哪句台词丢分,就改哪句。50 个回合后,翻蛋成功率 **+18%**,老师依旧只喊总分,却再也听不到 0 分。
落地长序列家务、仓储拣选——只有终点奖励,也能靠“聊天式回溯”练出细动作。
2. RFTF|「没有标签的跑酷闯关」
场景漫画深夜无人的跑酷馆,没有裁判、没有计时,只有一条铁律:“只要没撞墙,越往后状态越好!”RFTF 让机器人把这条时间自愈律当成隐形金币:每秒默认 +1 分,撞墙即归零。它用这股“自我发糖”信号先学出价值地图,再喂给 PPO 当“伪裁判”。零真实标签,机器人照样把翻越、着陆、急停跑成丝滑连招——真机滑台任务成功率↑20%。
落地无人工厂夜班、户外巡检——没人打分,靠“活得越久越优秀”也能自学成才。
3. TGRPO|「8 人副本,头部带飞」
场景漫画导演一喊开拍,8 台无人机同时冲刺“8 字绕旗杆”。一落地,评委秒出排行榜:1>2>…>8。TGRPO 把“头部 3 强”拖进 VIP 房间,“尾部 3 弱”当背景板——只比较“好 vs 差”两组均值,方差瞬间被吃掉。画家(策略)不再被偶尔爆冷带偏,样本效率×3,一圈顶三圈。导演笑说:“别人单挑 PK,我一次成团出道!”
落地集群无人机表演、仓储 AMR 车队——群体数据便宜,排名就是最好老师。
4. iRe-VLA|「256 核街机,一夜 10M 命」
场景漫画机房灯海闪烁,256 台街机同时开火——每台仿真器跑 4 k 步轨迹。GPU 中央大厅像“黑洞”实时回收录像,梯度平均后立即广播。一夜过去,累计跑出 10M 条真机等效经验——相当于单卡 3 年数据量。机器人从“菜鸟”直接肝到“速通常驻玩家”,第二天上线真机,动作稳得像开了外挂。
落地大工厂数字孪生、云仿真训练——有核就是任性,先让仿真跑爆,再让真机躺赢。
落地场景异构机器人云工厂——同一云端模型服务 arm、drone、hand、AGV 四种设备,换本体=换专家路由,零停机。
2. 未来 5 大「纯后训练」前沿方向(2025-2026)
| 后训练落地形式 | 代表工作 & 可复现入口 | |
|---|---|---|
| 1. 测试时扩展(Test-Time Scaling) | 推理阶段只采样 + 排序,权重不动;可再加在线 RL 给排序器。 | RoboMonkey(arXiv25)→ 用现有 OpenVLA-SFT 权重,推理时采 16 条轨迹,用 PRM 打分选最优;零额外训练。 |
| 2. 触觉-语言对齐(Tactile-DPO) | 把力觉图像 token 化后,直接对触觉-视觉-语言三元组做 DPO;无需重训 VLM。 | VTLA(RSS25)已开源触觉 tokenizer + 偏好数据;脚本 4 小时跑完。 |
| 3. 多机分布式 RL(FLaRe) | 预训练权重冻结,只分布式收集轨迹→ 用 PPO 或 TRPO 更新 policy head。 | FLaRe 代码默认「权重复制-梯度聚合」模式,只训 policy head 3B 参数量。 |
| 4. 长视界分层(LoHoVLA) | 两阶段后训练:① 高层子目标生成器 SFT;② 低层动作策略 PPO;VLM backbone 全程冻结。 | LoHoVLA 官方脚本 --freeze_vlm=true 一键开启纯后训练模式。 |
| 5. 自我进化(Self-Evolving VLA) | 模型只通过 DPO + 在线 RL 迭代;新任务生成 & 数据收集靠规则脚本,不碰预训练。 | AutoVLA(arXiv25)明确区分「任务生成」与「策略优化」,后者仅偏好学习 + RL。 |
① 测试时扩展(Test-Time Scaling)
把推理当成“临场抱佛脚”——模型权重锁死,上场前一口气画 16 张草图,观众(PRM)现场打分。挑最好的交卷。不重新学画画,只多烧几张草稿纸,准确率就悄悄爬升。
② 触觉-语言对齐(Tactile-DPO)
力觉图像被切成 token,跟视觉、语言排排坐。机器人靠“指尖恋爱滤镜”谈恋爱:刮手→差评,圆润→好评。4 小时对比训练,手感直接从“理工直男”升级“绅士手”。
③ 多机分布式 RL(FLaRe)
256 台仿真机同时开黑,只同步“手柄升级”,身体(VLM)原地不动。一夜跑出 10 M 条命,真机第二天上线,像开了“昨日存档”的外挂。
④ 长视界分层(LoHoVLA)
高层慢速写分镜,低层 100 Hz 打戏,两层各练各的。导演不减肥,演员狂练肌肉,10 k 步长剧情也能一条过。
⑤ 自我进化(Self-Evolving VLA)
机器人自己出卷子、考试、改错题——预训练大脑不改,只靠错题本循环升级。数据、策略、新任务像飞轮一样越转越快,技能树永动刷新。
4. iRe-VLA|「256 核街机,一夜 10M 命」
场景漫画机房灯海闪烁,256 台街机同时开火——每台仿真器跑 4 k 步轨迹。GPU 中央大厅像“黑洞”实时回收录像,梯度平均后立即广播。一夜过去,累计跑出 10M 条真机等效经验——相当于单卡 3 年数据量。机器人从“菜鸟”直接肝到“速通常驻玩家”,第二天上线真机,动作稳得像开了外挂。
落地大工厂数字孪生、云仿真训练——有核就是任性,先让仿真跑爆,再让真机躺赢。