
拓扑优化与CFD----高功率芯片设计微流体冷却系统
拓扑优化与CFD----高功率芯片设计微流体冷却系统
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
引言
注意到,黄大年茶思屋网站中提到了这样一篇文章,《Glacierware: Hotspot-aware Microfluidic Cooling for High TDP Chips using Topology Optimization》,这篇论文是关于高功率芯片设计微流体冷却系统的,于是,我决定写一篇关于拓扑优化与CFD的博客,来记录一下我的学习过程。同时值得注意的是,这项技术目前只有一家瑞士公司(洛桑Corintis公司)已经商业化并且尝试在迁移这套系统的应用场景,希望这篇文章能启发到更多researcher背景的公司创始人。
网站页面也给出了这项技术的主要原理和架构图,对于其底层数学的建模原理,我们后续会继续给出分析,而仿真落地的方案因为论文并未开源,目前还在探索过程中,后面有时间才会更新。
...
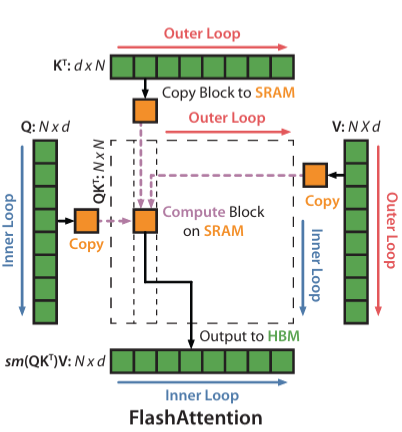
LLM底层架构---手撕flashattention1
LLM底层架构---手撕flashattention1
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
引言FlashAttention是近年来为优化自注意力机制(Self-Attention)而提出的一种高效算法,旨在解决传统注意力机制在大规模模型训练中的内存和计算瓶颈问题。其通过在硬件层面优化内存访问和计算策略,实现了显著的加速效果,尤其适用于大规模模型的训练。在其原始论文中(FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Aware Computation),作者提出了一种基于硬件友好的设计,使得计算过程中内存使用更加高效,从而加速了训练过程。FlashAttention 在保持精度的同时,显著降低了对 GPU 显存的需求和内存带宽的消耗。本文章参考了李理的博客(FlashAttention: 高效注意力机制的实现与优化),结合 ...
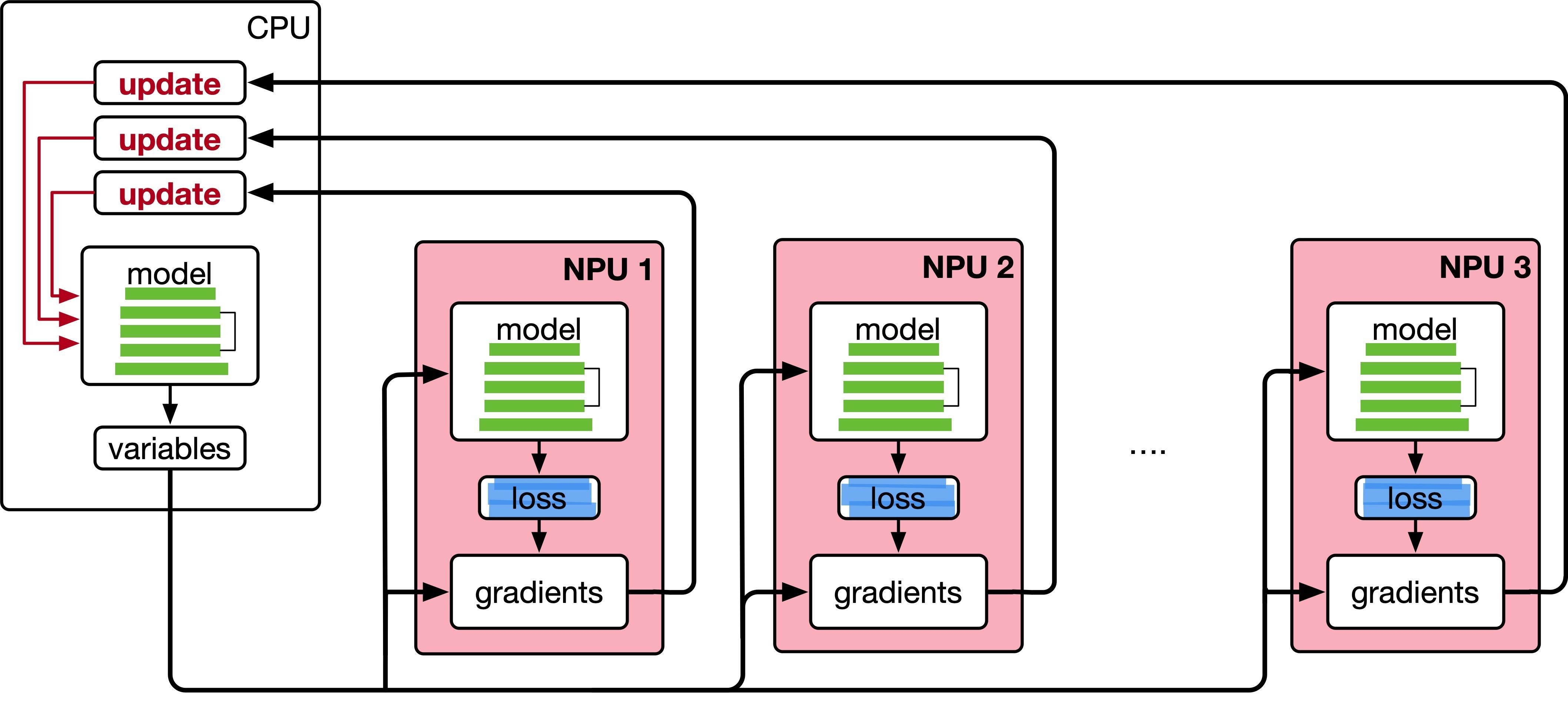
LLM分布式训练3---并行策略之流水线并行
LLM分布式训练3---并行策略之流水线并行
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的并行策略—-流水线并行。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例
LLM分布式训练4---Deepspeed实操
LLM分布式训练4---Deepspeed实操
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的Deepspeed实操。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例
LLM分布式训练2---并行策略之数据并行
LLM分布式训练2---并行策略之数据并行
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的并行策略。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例
数据并行的数学原理数据并行的核心思想是将整个神经网络模型复制到多个计算设备上,并将训练数据分成若干子集,分配到每个计算设备上。每个计算设备独立进行前向传播和反向传播,计算出本地的梯度,并将所有设备的梯度汇总以更新模型。这个过程的关键在于梯度的同步和平均。
在数据并行系统中,每个计算设备都有整个神经网络模型的模型副本(Model Replica),进行并行计算。每个计算设备只分配一个批次数据样本的子集 ...
LLM分布式训练3---集群架构
LLM分布式训练3---集群架构
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的并行策略。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例
LLM分布式训练1---基础知识篇
LLM分布式训练1---基础知识篇
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
引言随着大语言模型参数量和所需训练数据量的急速增长,单个机器上有限的资源已无法满足其训练的要求。需要设计分布式训练系统来解决海量的计算和内存资源需求问题。在分布式训练系统环境下,需要将一个模型训练任务拆分成多个子任务,并将子任务分发给多个计算设备,从而解决资源瓶颈。如何才能利用数万个计算加速芯片的集群,训练千亿甚至万亿个参数量的大语言模型?这其中涉及集群架构、并行策略、模型架构、内存优化、计算优化等一系列的技术。
本章将介绍分布式机器学习系统的基础概念、分布式训练的并行策略、分布式训练的集群架构,并以 DeepSpeed 为例,介绍如何在集群上训练大语言型。而这篇推送将主要介绍分布式训练的基础概念。
分布式机器学习系统的基础概念
分布式训练的并行策略
分布式训练的集群架构
实操DDP-以DeepSpeed 为例
...

MDP与蒙特卡洛抽样
2024数模国赛B题第4问|MDP与蒙特卡洛抽样
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
2024国赛已经匆匆落幕,但是,我们仍然需要总结经验,继续前行。本文将介绍强化学习中的蒙特卡洛方法,并给出一个具体的例子,帮助大家更好地理解这个概念。
在第二问中,因为所有的决策变量都是0-1变量,所以可以使用枚举法,或者蒙特卡洛模拟来求解。第三问,决策空间指数级别上升,暴力求解计算成本过高,所以可以引入启发式算法,比如模拟退火算法,遗传算法,粒子群算法,或者使用特殊的求解器,比如量子计算求解器。但是,在第四问中,决策变量是连续的,所以我们引入了马尔可夫决策过程(MDP),通过MDP根据当前检测结果和历史数据动态调整抽样率,以求的最优解,该方法与蒙特卡洛抽样法相结合,可以有效地解决该问题。
MDP决策推导马尔可夫决策过程(Markov Decision Process,MDP)是一种用于描述和控制具有不确定性的动态系统的数学模型。它由状态空间、动作空间、转移概率和奖励函数组成。在MDP中, ...

如何科学上网|clash安装教程
如何科学绿色上网|clash安装教程
引言
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
Clash for Windows 是代理工具Clash在Windows系统的图形客户端,同时还支持Linux、macOS系统,功能强大且支持多种代理协议,如V2Ray、Trojan、Shadowsocks(R)、Socks等协议。
2023年11月2日Clash for Windows作者Fndroid删除了该项目GitHub仓库并宣布停更,原因未知(进去坐大牢了),但已发布版本均正常可用。
clash项目是完全免费的,但是其缺点也显而易见,由于缺乏足够人手维护,虽然一直以来没有出现过问题,不过稳定性还是被人所质疑。
如果大家对其安装或者使用不是很有信息,就使用Sakuracat(下载链接)。每月10块不到,就可以享受非常稳定的代理服务。不过由于其没有全局代理服务,无法登录使用GPT等需要全局代理的网站。
一.下载 ...

AI+math|从Alphafold说起
AI+math|从Alphafold说起
引言
作者:@同济大学 刘越
Github ID:@miracle-techlink
联系邮箱:miracle.techlink@gmail.com
校内邮箱: 2254018@tongji.edu.cn
特别感谢以下组织和个人提供的帮助:Datawhale开源学习社区 (点击链接进入其github教程仓库)集智俱乐部(https://pattern.swarma.org/user/116904) (点击链接进入官网)@同济大学数学科学学院陈小杨教授 (邮箱:xychen100@tongji.edu.cn)
2024年诺贝尔化学奖授予大卫·贝克(David Baker)、戴米斯·哈萨比斯(Demis Hassabis)和约翰·江珀(John M.Jumper),以表彰他们在蛋白质设计和蛋白质结构预测领域作出的贡献。他们与Deepmind公司在2020年发布的lphaFold2算法,在蛋白质结构预测领域取得了重大突破,其预测结果与实验结果高度一致,为生物科学领域带来了革命性的影响。我们今天就一起走进AlphaFold的世界,了解其背后的原理 ...